Tecnofilosofo, una figura emergente?

Un giorno ho sognato di vedere studiosi di filosofia prendere le loro conoscenze teoriche e usarle per costruire delle tecnologie.
Da quel momento è nato in me il concetto di “tecnofilosofo”.
In questo articolo vorrei presentarvi tre strade attraverso le quali la filosofia potrebbe concretamente lavorare nell'informatica.
Il tecnofilosofo: l'etica dell’informatica, l'ontologia informatica, la logica applicata e Prolog

La prima strada riguarda l’etica dell’informatica come ramo dell’etica applicata.
La seconda strada riguarda l’ontologia informatica come classificazione e tassonomia di ogni cosa, un ramo che interessa non solo la filosofia, ma anche l’informatica e l’ingegneria.
La terza strada è quella che chiamo logica applicata. Si tratta dell’insieme intero di quegli ambiti in cui la logica ha trovato concreta applicazione nella tecnologia. Si passa dall'elettronica digitale alla programmazione. In particolare vorrei parlare di intelligenza artificiale e di Prolog (Programmer en logic = programmare con la logica).
1) Etica dell’informatica
Esiste una letteratura sconfinata in filosofia sul tema dell’etica e la tecnologia, ma non è di questo che ho intenzione di parlare. Vorrei piuttosto concentrarmi sull'etica dell’informatica e in particolare sul testo di Luciano Floridi: Ethics of information.
Si tratta di un libro che cerca di dare un fondamento alle etiche dell’informazione partendo dalla pluralità di esse.
Floridi sottolinea come le etiche dell’informazione siano molte:
etica del computer, etica dei robot, etica dei dati, ecc. Sono ben noti, ad esempio, i dieci comandamenti del computer:
- 1) Non utilizzare un computer per danneggiare altre persone.
- 2) Non interferire con il lavoro al computer degli altri.
- 3) Non curiosare nei file degli altri.
- 4) Non utilizzare un computer per rubare.
- 5) Non utilizzare un computer per ingannare.
- 6) Non utilizzare o copiare software che non hai pagato.
- 7) Non utilizzare le risorse dei computer di altri senza autorizzazione.
- 8) Non appropriarti della produzione intellettuale degli altri.
- 9) Pensa alle conseguenze sociali del programma che scrivi.
- 10) Usa il computer in modo da mostrare considerazione e rispetto.
Sono sicuramente un insieme di regole molto discusse, per esempio diversi hacker non si riconoscono in tutti questi principi. Ma non è questo il modello che segue Luciano Floridi nel suo testo. Egli intende piuttosto trovare un fondamento generale per tutte le etiche dell’informazione. Dunque non troviamo assolutamente alcuna forma di legge morale espressa esplicitamente nel testo di Floridi, ma vediamo una serie di problematiche molto importanti sull'applicazione dell’etica alla tecnologia e la costruzione di alcuni modelli per analizzare l’etica della tecnologia stessa.
Luciano Floridi autore di Ethics of information (l'etica dell’informatica e il tecnofilosofo)

Potrebbe interessarti anche: Introduzione all’intelligenza artificiale (AI)
Nel libro di Floridi troviamo un modello come l’RPT (Resource, Product, Target). Prendendo un qualsiasi agente A, secondo questo modello l’agente A può accedere a certe informazioni come risorsa (Resourse), produrre egli stesso informazioni (Product), influenzare l’ambiente informazionale (Target).
Questo ambiente informazionale è normalmente definito da Luciano Floridi con il termine di infosfera.
L’infosfera si definisce come spazio informazionale ed è composta da differenti livelli di astrazione (Level of abstraction o LoA).
Funziona come il computer: la realtà, anche quella ha i suoi livelli di astrazione. Ogni livello di astrazione è un insieme di osservabili. Il termine “osservabile” è sicuramente ripreso dall'informatica da Luciano Floridi, lo troviamo per esempio nel pattern design Observer.
Tuttavia qui Floridi per osservabile intende dire una qualsiasi variabile tipata.
Una variabile tipata è un nome a cui viene assegnato un valore di un certo tipo preciso. Il valore della variabile è un dato e questo dato ha un tipo specifico che può essere numerico, stringa, ecc. Il dato può essere un nome, un numero di telefono o anche un oggetto completo.
Ogni livello di astrazione è caratterizzato da un sistema e in questo sistema troviamo un insieme di osservabili. Allo stesso tempo, sostiene Floridi, un livello di astrazione genera un modello che identifica una serie di proprietà che sono attribuite agli osservabili stessi.
In questo ci accorgiamo che il modello di cui parla Floridi ricorda molto le classi modello di Java che definiscono, appunto, le proprietà di un oggetto. Gli osservabili potrebbero essere le istanze degli oggetti.
A questo punto l’agente A sembra essere proprio un osservabile come gli altri nel sistema. Infatti vediamo spesso Floridi definire gli umani come degli Inforg, ossia degli organismi informativi.
Le cose si complicano quando dobbiamo tenere conto di fenomeni come la telepresenza, che sono fenomeni tipici in informatica (pensate alla video conferenza).
Questo fenomeno pone non pochi problemi di carattere filosofico interessanti, perché si tratta di tenere conto del fatto che un individuo pur trovandosi da tutt'altra parte, è allo stesso tempo presente in un altro luogo, almeno grazie ad uno schermo.
A questo punto nel testo di Floridi si trova una distinzione tra lo spazio locale di osservazione (Local Space of Observation) e lo spazio remoto di osservazione (Remote Space of Observation).
Ma i veri problemi dell’etica dell’informatica sono principalmente due:
avere un modello etico che possa applicarsi a tipi di entità che non hanno libertà o intenzioni e possono non essere nemmeno degli agenti nel senso classico del termine;
avere un modello multiagente.
Per esempio, se prendiamo come esempio un modello classico di morale come quella kantiana, troviamo un agente morale di cui si presuppone la libertà nell'agire e si presuppongono delle intenzioni.
Kant giustifica la libertà sulla mera legge morale sostenendo che: se devi, allora puoi.
In ambito informatico, computer o intelligenza artificiale, ovviamente, non abbiamo a che fare con enti liberi. Molto spesso non abbiamo a che fare nemmeno con dei veri agenti in senso tradizionale. Per esempio non consideriamo agente un malware.
Per analizzare l’etica dell’informatica Luciano Floridi sceglie di usare un modello orientato agli oggetti. In questo modello troviamo un agente, un paziente, l’iterazione tra i due, le informazioni accessibili all'agente, l’ambiente dove l’agente e il paziente sono localizzati.
L’agente è la sorgete dell’azione, lo stimolo, il messaggio. Il paziente, invece, subisce l’azione.
L’azione morale, spiega Floridi, è un processo informativo che va dall'agente al paziente. Ovviamente questo modello si lega perfettamente con il precedente, nella misura in cui il precedente spiega la relazione di un agente con l'infosfera in generale.
Il modello orientato agli oggetti, come è ovvio, si ispira alla programmazione orientata agli oggetti.
La programmazione orientata agli oggetti è un metodo di programmazione molto intuitivo che ha sostituito in grande parte la programmazione procedurale precedente.
Nella programmazione orientata agli oggetti troviamo due principali entità: le classi e gli oggetti. Le classi sono usate come modelli che definiscono proprietà e metodi degli oggetti.
Nell’RPT abbiamo le classi come modello e gli oggetti come osservabili. Ogni tipo di oggetto è caratterizzato da degli attributi locali, ossia attributi della classe a cui appartiene, ma anche da attributi ereditati da classi padre.
Ma fino a quando parliamo di esseri umani nell’infosfera possiamo parlare di agenti liberi (free agent), il problema comincia con gli agenti artificiali (artificial agent), i quali costituiscono il principale problema dell’etica dell’informatica.
Il problema principale sta nel concepire questi agenti artificiali come sorgenti di azioni morali.
Infatti sicuramente gli agenti artificiali si comportano in un certo modo a seconda di come sono programmati, ma non per questo bisogna pensare che un programmatore, poiché una macchina a guida autonoma da lui stesso programmata ha un ucciso un uomo, debba necessariamente finire in carcere.
Questo argomento è costruito da Luciano Floridi in analogia con il caso dei genitori che educano male i figli o che falliscono nella missione di educatori. I modelli classici della morale rimangono troppo antropocentrici e non riescono a porre basi sufficienti per un’etica dell’informatica. Infatti in quei modelli l’agente morale non può che essere un umano.
Luciano Floridi, invece, definisce come agente un sistema inserito in un ambiente, capace di esercitare un potere su di esso, ossia di produrre effetti.
Oltre a questo l’agente ha tre caratteristiche:
l’interattività, secondo la quale l’agente e l’ambiente possono agire l’uno sull'altro;
l’indipendenza, secondo la quale un agente è in grado di cambiare il proprio stato indipendentemente dall'ambiente;
l’adattabilità, secondo la quale le iterazioni dell’agente possono cambiare le regole transitorie con le quali cambia il suo stato.
Giustamente Floridi nota che alcune di queste proprietà come l’interattività dipendono anche dalla capacità di poter osservare certi fenomeni, i quali possono verificarsi ad un livello di astrazione specifico, magari a noi stessi non accessibile.
Perché un’agente sia morale deve essere capace di azioni morali.

Potrebbe interessarti anche: Java spiegato ai filosofi
Floridi definisce l’azione morale come azione che causa bene o male, ossia che è in grado di aumentare o diminuire il grado entropia nell'infosfera.
L’agente artificiale non viene considerato agente morale solitamente per i seguenti motivi: non ha un fine, non ha intenzionalità, non è libero e non è responsabile.
Ovviamente un agente artificiale ha un fine e questo dipende sempre da chi lo ha programmato e pensato quell'agente. In secondo luogo per Floridi l’agire morale non implica in alcun modo l’intenzionalità, per questo può essere attribuito anche ad uno zombie o un agente artificiale. Oltretutto Floridi sottolinea il fatto che per agire libero può essere inteso semplicemente un agire non in senso deterministico. Mentre il problema della responsabilità viene spostato da Floridi da una concezione troppo antropocentrica alla considerazione secondo la quale l’agente artificiale va semplicemente pensato come una sorgente di male o di bene.
Per chiarirci Floridi quando parla di agenti artificiali ha in mente non solo robot, intelligenza artificiale e computer, ma anche singole app, antivirus, malware, ecc. Ogni nostra esperienza degli agenti artificiali, ad ogni modo, è sempre mediata da un’interfaccia.
Una morale che si rispetti ha sempre dei concetti definiti di bene e di male.
In questo caso nel testo di Floridi si parla del male artificiale. Il male artificiale viene definito da Floridi come uno o più messaggi negativi che partono dall’agente A e che portano delle trasformazioni nello stato del paziente P che possono danneggiarlo.
Il male come tale si riferisce dunque solo a certe azioni che avvengono nel processo informativo. Ovviamente il male in sé o il diavolo dell’informatica non esiste.
Le capacità morali di un agente qualsiasi dipendono da come l’informazione è processata e da quanta informazione viene acquisita dal tale agente. È chiaro che un qualsiasi agente con la migliore delle sue volontà se non ha informazioni sufficienti o ha quelle sbagliate può fare le scelte sbagliate. Per questo è importante lavorare sull'informazione nell'infosfera. Non si tratta di aumentarne la quantità. Ce ne sono fin troppe di informazioni. Si tratta di aumentare la qualità di esse.
Quando parliamo di etica dell’informatica, inoltre, dobbiamo riferirci ad un’etica multiagente.
Bisogna tenere conto da un lato che certi dispositivi possono danneggiarne altri o possono danneggiare persone, dall'altro dobbiamo tenere conto del fatto che questi dispositivi sono programmati e costruiti, dunque devono essere anche programmati e costruiti per agire secondo regole morali.
Il libro di Floridi, ovviamente, tratta di un sacco di altri temi come quello della privacy o dell’accesso all’informazione. Purtroppo penso sia uno dei pochissimi testi in filosofia a trattare seriamente del tema, ma è sicuramente un buon punto di inizio. A prescindere da questo, tutto il mondo informatico si sta muovendo nella direzione dell’etica e di una giurisprudenza informatica oramai molto tempo.
In questo contesto lo studioso di filosofia e tecnologia o tecnofilosofo potrebbe lavorare a livello di consulente etico.
Per esempio nelle etiche applicate esiste già la professione del consulente aziendale, come persona che usa determinate tecniche, quali il dialogo socratico, applicate alle aziende con lo scopo di sviluppare buone soft skill nei dipendenti.
Oggi, ad esempio, si parla spesso di manager più riflessivi.
In questo contesto una figura di etico dell’informatica potrebbe essere molto interessante.
L’etica dell’informatica dovrebbe lavorare su molti settori e livelli: etica del computer (etica applicata ai software), etica dei dati (problema della privacy, raccolta dati) ed etica dell’intelligenza artificiale.
Tra questi ambiti, molto probabilmente, quello che più mi interessa è sicuramente quello dell’intelligenza artificiale. In particolare si parla di robot, intelligenza artificiale debole come Alexa o macchine a guida autonoma.
Il primo punto sta nell'individuare una serie di principi etici validi per il programmatore dell’intelligenza artificiale da seguire nel processo di programmazione.
Il secondo punto sta nel capire quali sono le regole che deve seguire l’agente artificiale per comportarsi moralmente nella relazione con altri agenti umani.
Nell'intelligenza artificiale esistono principalmente due correnti:
il simbolismo e il connessionismo.
Il simbolismo pensa l’intelligenza come manipolazione di segni in accordo a regole. In questo senso possiamo pensare di programmare la macchina esperta, definendo le regole che essa stessa deve seguire per raggiungere un certo fine.
Il connessionismo pensa l’intelligenza artificiale come capacità di classificare dati e in base alla classificazione perseguire determinati fini definiti. Nel connessionismo troviamo le reti neurali e il machine learning. Si tratta, per esempio, di quelle tecnologie che sono in grado di riconoscere un volto in un’immagine.
In questo contesto l’efficienza dell’intelligenza artificiale dipende dai dati che gli vengono forniti.
Ad esempio Amazon che ha incominciato a fare selezione del personale con l’intelligenza artificiale, ad un certo punto si è accorto che, avendo pochi dati relativi alle donne, era nata una forma di discriminazione verso il sesso femminile. Da quel momento Amazon ha incominciato una campagna a favore dell’assunzione delle donne in informatica.
Alcuni studiosi di filosofia sono già stati coinvolti per il problema dei così detti “algoritmi sessisti”.
Oltre a ciò troviamo proprio il problema su quale modello usare per i robot nella programmazione di un agente morale. Molti trovano estrema confidenza con il modello utilitarista, che è quello secondo il quale ogni azione morale deve puntare al bene del maggior numero di persone.
Questo modello è molto seguito perché è semplice da usare: si tratta di fare un calcolo dei beni e dei piaceri. Ma secondo questo modello, ad esempio, la bomba atomica era un bene perché aveva posto fine ad una guerra mondiale.
Il modello kantiano, invece, stenta a farsi strada.
Eppure io penso che non sia impossibile seguire proprio quel modello lì. Infatti sarebbe sufficiente programmare una macchina con questa regola:
“Agisci in modo che la massima della tua volontà possa valere come legge universale”.
Il software in questione prende in input una massima (ad esempio: “Restituire tutto ciò ti è stato imprestato”), cerca di capire se questa massima si accorda alla legge sopra scritta e, se le stanno così, ci dirà che è un imperativo categorico, altrimenti ci dirà che non lo è.
Se è un imperativo categorico aggiungerà quell'imperativo alle regole che deve seguire nella condotta.
Il problema centrale sta nel capire per una macchina se la massima si accorda alla legge kantiana. Per questo Kant usava questo esempio: immaginare un mondo in cui tutti agiscono secondo quella massima e vedere cosa succede.
Si tratterebbe per la macchina, in questo caso, di trarre delle conclusioni da una simulazione di una realtà in cui degli individui agiscono secondo quella massima. In questo modo potremmo avere il nostro agente intelligente kantiano.
2) Ontologia informatica
Un ramo molto interessante della filosofia sull'informatica è certamente l’ontologia informatica. Lo è perché rappresenta una materia trattata, non solo dai filosofi, ma soprattutto dagli informatici.
Quello che dirò sarà in buona parte basato sul testo sull'ontologia informatica di Barry Smith contenuto in Storia dell’ontologia, a cura di Maurizio Ferraris.
La situazione attuale è la seguente:
da un lato l’informatica sente l’importanza dell’ontologia e se ne serve in diversi settori come quello delle basi dati o quello dell’intelligenza artificiale,
dall'altro la filosofia è tornata in maniera massiccia ad interessarsi di ontologia, proprio perché oggi, anche grazie all'informatica, i tipi di enti si sono moltiplicati tantissimo (siti web, oggetti digitali, realtà aumentata, apps, ecc.).
Questo costituisce, infatti, uno dei settori più importanti quando si parla di comunicazione tra filosofia ed informatica.
L’ontologia informatica è a tutti gli effetti sia qualcosa che coinvolge i filosofi come branca della filosofia, sia qualcosa che riguarda gli informatici, soprattutto per quello che riguarda i dati.
Che cos'è l’ontologia?
Spesso si fa risalire il termine ontologia a Parmenide, dichiarando Parmenide il vero padre del pensiero ontologico. Ciò presumibilmente deriva dal fatto che Parmenide è il filosofo dell’Essere, colui che si interroga su ciò che è. Questo fatto può creare una confusione.
La filosofia di Parmenide è principalmente incentrata sulla metafisica, ossia la scienza dell’essere. Tuttavia è chiaro che quel che afferma Parmenide ha delle conseguenze ontologiche.
L’ontologia, infatti, non si occupa tanto dell’essere, quanto piuttosto dell’esistenza.
Parmenide afferma dell’Essere che è e del non Essere che non è. L’Essere non può non essere, per questo solo l’Essere è. L’ontologia di Parmenide, dunque, è dell’Essere eterno.
Tuttavia è Aristotele il riferimento più adatto per lo studio dell’ontologia. In questo contesto risultano molto importanti la sua metafisica e la sua dialettica.
Se la metafisica appare così strettamente collegata all'ontologia dipende semplicemente dal fatto che non possiamo definire come esistenti degli esseri senza sapere prima cosa sono. L’essere di una cosa può essere fatto coincidere con il suo esistere, ma l’essere è sempre in un dato modo ed è il modo in cui è l’ente che permette di creare una tassonomia di tutti gli enti.
Da qui nascono le categorie di Aristotele e questo è il vero motivo per cui la metafisica di Aristotele in questo contesto suscita tanta attenzione.
Le famose categorie aristoteliche sono:
sostanza, qualità, quantità, luogo, tempo, avere, relazione, agire, patire, stare.
Queste categorie sono i generi sommi. Aristotele stesso aveva in mente un modello dove queste categorie costituivano la base. L’essere si dice in molti modi, secondo Aristotele. I modi dell’essere sono le categorie. Le categorie sono, inoltre, degli strumenti di classificazione. Ma il vero metodo aristotelico resta sempre quello della dialettica spiegato nei Topici dell’Organon. Questo metodo parte da formulazioni di ricerca sull'oggetto della dialettica.
La dialettica, infatti, si pone come scopo la definizione. La definizione è possibile attraverso una classificazione dell’oggetto ricercato per generi e specie. Questa classificazione in Aristotele segue tre livelli: genere, specie e individuo. Questi tre livelli sono gerarchici: ogni specie ha un genere, ma ogni genere ha più specie. Genere è, ad esempio, l’animale, specie è l’uomo.
L’individuo, invece, è l’ultimo degli elementi. L’individuo è la sostanza prima non ulteriormente scomponibile.
In tempi più recenti il filosofo Roderick Chisholm ha proposto un metodo per l’ontologia che certamente ha alle spalle gli studi di Aristotele.

Potrebbe interessarti anche: Tecnofilosofia: il rapporto difficile tra la filosofia e la tecnologia
Secondo Chisholm l’ontologia deve avere queste tre caratteristiche:
- 1) Deve avere l’aspetto di un grafo ad albero.
- 2) Il grafo segue una gerarchia: esistono entità superiori e altre entità inferiori. Si parte dai primi nodi e poi si comincia a dividere.
- 3) Il grafo non può contenere cicli o doppioni. Nel senso che non ci possono essere rombi, perché questo porterebbe una specie ad appartenere a più generi.
Esistono principalmente due modi di costruire un’ontologia:
la top-down, ossia partire da categorie generali o generi e dividere per specie;
la bottom-up, ossia partire dalle specie e risalire verso i generi.
Di fronte alla costruzione di un’ontologia si rilevano due problemi:
la definizione di un albero ontologico completo;
la presenza delle partonomie, oltre che delle tassonomie.
È forse stato il sogno dei filosofi quello di costruire un albero ontologico completo, ma al momento nessun filosofo è mai riuscito in questa impresa.
Quello che capita spesso è che si costruiscano delle ontologie più specifiche, per esempio una tassonomia degli oggetti sociali, una tassonomia della tecnologia, ecc. L’altro problema riguarda il fatto che una classificazione completa di tutti gli enti per specie e generi non comprende l’analisi dell’ente stesso nelle sue parti.
Una volta che dividiamo gli animali nelle loro specie, sino ad arrivare agli ultimi elementi, possiamo ancora scomporre gli animali nelle parti: le zampe, le orecchie, il becco, ecc.
Su questo punto devo ammettere che il testo di Barry Smith mi ha sorpreso perché penso che la maggior parte dei filosofi tenderebbero a trattare la partonomia come un problema a parte.
In generale questa questione mette in relazione l’ontologia con un’altra branca importante della filosofia che è la mereologia, la scienza che studia la relazione tra le parti e il tutto. Infatti una cosa è dire che la rondine è un uccello e che gli uccelli, in quanto uccelli, hanno il becco, ma dividere l’ente rondine in parti come le ali, il becco o altro ancora, è cosa diversa.
Proprio l’ontologia dei filosofi è stata ripresa dall’informatica, in particolare da autori come S.H. Mealy.
Come osserva Barry Smith, Mealy, in un testo sui fondamenti del data modelling del 1967, cita Quine e il suo saggio noto per essere il fondamento dell’ontologia contemporanea.
Orman Quine, infatti, è a tutti gli effetti il vero padre dell’ontologia contemporanea, molto più che Heidegger. Quine ha scritto un saggio dal titolo “Su ciò che esiste”.

Potrebbe interessarti anche: L’ontologia dei siti web e la realtà di internet
Secondo Quine la vera domanda dell’ontologia è la seguente: che cosa esiste di tutto ciò che c’è?
Nella filosofia abbiamo due modelli estremi dell’ontologia che possono essere facilmente rappresentati da due paesaggi opposti come la giungla e il deserto.
Esistono, dunque, delle ontologie che pullulano di entità di tipo molto differente e altre che riducono gli enti ad un numero sempre minore di esistenti.
Per esempio potremmo affermare l’esistenza di qualsiasi cosa, anche dei personaggi dei romanzi, oppure potremmo ridurre ogni cosa agli atomi o alle particelle subatomiche, sostenendo che questi ultimi sono le uniche cose che esistono.
Quine, ad esempio, sostiene che esistono soltanto particelle in campi di forza e ha scritto il testo prima citato proprio contro altri filosofi come Alexius Meinong.
Meinong sosteneva che siccome ogni atto mentale è intenzionale e per questo punta a qualcosa, esiste qualcosa che è pensato e che non esiste solo nel pensiero. Questo qualcosa più che esistere sussiste e sussiste in qualche mondo ideale. In questo contesto anche un’entità impossibile risulta come sussistente, in quanto non potrebbe essere nemmeno pensata, se non fosse così.
Ma nel testo vediamo che Quine critica chi afferma l’esistenza dei possibili perché ogni cosa è potenzialmente possibile: un uomo grasso nel vano della porta, un uomo calvo nel vano della porta, ecc. Certamente è molto difficile dimostrare l’esistenza di entità come i personaggi dei film o oggetti impossibili come il quadrato rotondo.
Tuttavia, d’altra parte, ridurre ogni cosa a nuvole di atomi pone moltissimi problemi, perché tutto viene ridotto alla materia e si manca completamente di comprendere un sacco di enti di natura sociale come gli Stati, i cittadini, il denaro o le opere d’arte.
È facile comprendere che una buona via di mezzo tra due estremi ontologici è possibile. Tuttavia quello che conta del testo di Quine è il fatto che viene definito un nuovo modo di fare ontologia usando la logica.
Si fa ontologia con il quantificatore esistenziale.
Secondo questo particolare concetto di esistenza, l’esistenza è quantità. Esiste qualcosa, quando c’è almeno un esemplare di quel qualcosa, altrimenti non esiste. Noi diciamo, ad esempio, che non esistono i draghi, semplicemente perché non ci sono esemplari di draghi in questo mondo.
Proprio questa forma di ontologia è stata ripresa ed impiegata dall'informatica in determinati settori come le basi dati e l’intelligenza artificiale. Le basi dati sono i database che sono delle collezioni di tabelle.
Ogni tabella ha diverse colonne che contengono differenti tipi di dati.
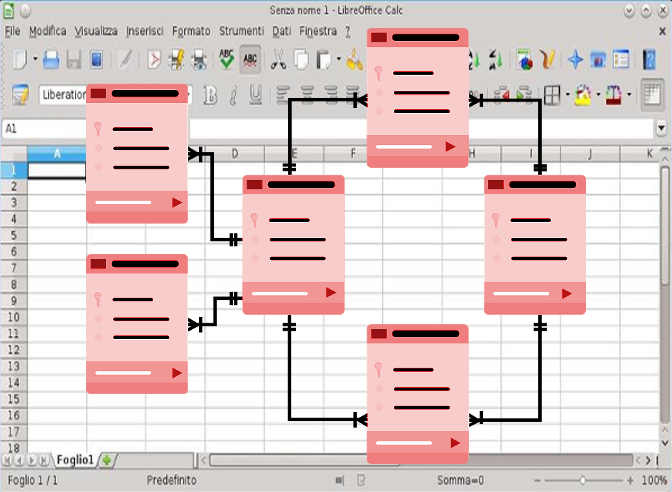
Ogni colonna ha il suo nome e indica un certo tipo di dato che può essere una stringa, numeri interi, ecc. Ogni riga della colonna rappresenta una tupla con il singolo record e ogni riga è identificata da un id.
Nelle basi dati esistono principalmente tre schemi generali:
- 1) schemi implementativi: descrivono i modelli fisici di immagazzinare i dati e il codice del programma.
- 2) schemi concettuali: nei quali termini formulare rappresentazioni dichiarative.
- 3) schemi di presentazione: che sono applicati a interfacce esterne per scopi di comunicazione con l’utente.
Nelle basi dati, infatti, troviamo schemi di entità-relazione dove vengono rappresentate le tabelle con le loro relazioni. In questo schema eseguiamo una basilare operazione di ontologia: identificare le entità principali che sono interessate in un certo contesto. Per esempio se costruisco un database di una concessionaria avrò come entità interessate le auto in questione, le fabbriche da cui vengono queste auto, i proprietari di queste auto, ecc.
Ognuna di queste entità ha delle proprietà che coincidono con le colonne della tabella. Ad esempio un veicolo ha una targa, una marca, una cilindrata, un certo numero di cavalli, ecc. Per chi conosce la programmazione orientata agli oggetti, queste entità ricorderanno le classi modello che definiscono proprietà e metodi di un oggetto.
Il fatto stesso che il modello orientato agli oggetti è così diffuso nell'informatica dipende dal successo dell’ontologia filosofica nell'informatica stessa. La differenza nei database sta nel fatto che sono entità singole, ma sono sempre al plurale, essendo che le tuple (ossia le righe della tabella) sono certamente molteplici. Infatti ogni auto avrà la sua targa, la sua marca, ecc.
Non ci sono metodi o capacità delle entità in questione, ma ci sono relazioni tra tabelle. Lo schema entità-relazione, infatti, rimanda all'algebra relazione della logica. Le relazioni, tuttavia, non sono del tipo di parentela, sono relazioni tra le entità come quella di proprietà delle auto.
Ogni tabella può essere in relazione con altre tabelle in tre modi: 1:1, 1:n, n:n.
La prima relazione è di un elemento con un altro solo come la capitale con un determinato paese.
La seconda relazione è di più elementi con uno solo, come gli studenti che fanno tutti parte della stessa classe.
La terza relazione è di più elementi con più elementi, come con gli utenti iscritti e i canali youtube.
Il modello entità-relazione, tuttavia, è molto astratto.
Dopo aver individuato le entità e le relazioni bisogna definire tutte le proprietà che si intendono attribuire alle entità o alle relazioni, quando è il caso. Nell'ultima fase si implementa a tutti gli effetti il database costruendo le tabelle con righe e colonne, inserendo i vari dati.
L’ontologia, in realtà, non interessa solo le basi di dati, ma anche l’intelligenza artificiale.
Creare un modello che definisca gli enti che popolano il nostro mondo significa definire uno schema che ci permette di comprendere come è costruito il mondo con cui entriamo in relazione. Anche per un robot esiste lo stesso problema:
bisogna definire il modello che descrive il mondo con cui il robot stesso entrerà in contatto.
Patrik Hayes, autore citato da Barry Smith come esempio positivo di applicazione dell’ontologia in informatica, ha scritto un testo con lo scopo di definire un’ontologia dei liquidi.

L’idea di base di Hayes consiste nel costruire una fisica ingenua servendosi di uno strumento che, come nota lo stesso Smith, ricorda quello che il filosofo Carnap chiamava: logica applicata.
Questo è sicuramente l’inizio di uno studio serie su un’ontologia per intelligenze artificiali e futuri robot. Quello che serve non è una descrizione reale di come è il mondo. Non ci interessa sapere, per esempio, se esistono davvero mouse e computer, oppure se in realtà sono solo particelle in campi di forza.
Quello che ci interessa è come è costruito il mondo per il senso comune.
Questo mondo non è tanto fatto di atomi o elettroni, quanto piuttosto da cose solide, liquide o aeriformi . Per questo motivo progetti simili sono molto importanti.
La grande difficoltà, tuttavia, sarà derivata dal fatto che questo modello deve essere molto dettagliato, coprire tutti i fenomeni fisici e dunque tenere conto di un sacco di variabili. Insomma il nostro mondo del senso comune, pur essendo più semplice di un altra realtà come quella quantistica, possiede comunque una notevole complessità perché deve racchiudere un sacco di oggetti naturali e sociali, relazioni, leggi della fisica e molto altro ancora.
L’obbiettivo finale dovrebbe essere quello di costruire un’ontologia che permetta di costruire un robot che veda e interagisca con un mondo che è come il nostro. Perché solo in questo modo il robot e l’umano potranno realmente intendersi.
Ricordatevi questo: Johan von Benthem sostiene che l’intelligenza artificiale è la prosecuzione della logica con altri mezzi. Ma questo non va inteso come se certi ambiti dovessero sostituirsi alla filosofia, come pensava Heidegger con la cibernetica. Si tratta piuttosto di pensare una nuova filosofia, una tecnofilosofia.
3) Logica applicata
Logica applicata è un termine che usava il filosofo Rudolf Carnap e che contrapponeva alla logica formale.
Io, personalmente, in questo caso, intendo con questo termine qualcosa di molto diverso da quel che ha in mente Carnap. Io intendo tutte le applicazioni che ha avuto la logica all'interno della tecnologia. Con questo mi riferisco all’elettronica e all’informatica.

Nel caso dell’elettronica è la logica booleana, il serie e il parallelo che costituiscono gli elementi logici del digitale. Nel caso dell’informatica si parla di come viene usata la logica all'interno del software, ossia nella programmazione.
L’intera programmazione viene dalla logica lineare e la logica stessa trova un impiego massiccio nei fondamenti della programmazione:
i condizionali, gli operatori logici, il booleano, le funzioni, ecc.
Tuttavia se si cerca più a fondo è proprio il ramo dell’intelligenza artificiale ad essere più influenzato dalla logica, essendo la logica stessa una formalizzazione del linguaggio e del pensiero.
L’intelligenza artificiale segue due correnti principali: i simbolisti e i connessionisti.
I simbolisti credono che l’intelligenza consista in una manipolazione di simboli secondo regole.
I connessionisti pensano l’intelligenza a partire da reti neurali che capaci di fare previsioni sulla base della montagna di dati che gli vengono forniti.
Da qui derivano due tipi di tecnologie: le macchine esperte e le reti neurali. Tra i linguaggi che si occupano della programmazione delle macchine esperte troviamo il linguaggio Prolog. Anche se oggi la maggior parte dell’Ai è deep learning o machine learning, anche un linguaggio campione delle reti neurali come Python ha i suoi strumenti per lavorare con Prolog: Pylog.
Prolog è linguaggio che è stato ideato nei suoi fondamenti teorici da Robert Kowalski, un logico e scienziato del computer.
Successivamente è stato implementato da Alain Colmerauer, uno scienziato del computer francese che è considerato il vero padre del linguaggio Prolog.
Prolog vuol dire Programmation en logique ed è un linguaggio che si basa sulla logica predicativa di Frege.
La logica predicativa di Frege parte da una intuizione fondamentale: rappresentare tutti gli enunciati della forma predicativa come funzioni. Esempio: “Socrate è un uomo” diventa Uomo(Socrate), che formalizzato si trasforma nella formula “Us”. Su questo principio e gli altri della logica si basa anche il linguaggio Prolog.
Prolog si compone di termini, regole e fatti.
I termini possono essere degli atomi, dei numeri, dei termini composti, delle liste, una stringa. Gli atomi sono nomi generici, i numeri sono interi o decimali, i termini composti sono termini composti da un atomo che ha uno o più argomenti, le liste sono una collezione di termini separati dalle virgole.
Atomo: y, red, ‘il posto che corre’;
Numero: 1, 1.3, 34;
Lista: [2,3, 56], [cane, lupo, tigre];
stringa: ‘C4@rr5’, ‘la volpe è un animale’, ‘impossibile’;
Un fatto è una certa relazione di predicazione di una lettera predicativa rispetto ad un termine.
dog(fido) // significa che fido è un cane
human(socrate) // significa che Socrate è un uomo
La regola, invece, indica un rapporto condizionale tale per cui, se vale una certa cosa, allora ne consegue una certa altra.
animal(X):-
dog(X)
Questa espressione significa che se una cosa è un cane, necessariamente è un animale.
mortal(X):-
human(X)
Quest’altra espressione significa che se una cosa è un uomo, necessariamente è un animale.
In questo caso la risposta della macchina quando eseguiamo questo codice dipende dal valore che inseriamo nella X, se quel valore è un uomo o un cane, allora sarà vero che è mortale o che è un animale. Dunque la macchina ci risponde semplicemente con un true o con un false.
Ma come fa a saperlo?
Beh, semplicemente siamo noi a definire i fatti, come quando scriviamo human (socrate). In questo caso, data una certa regola chiediamo alla macchina se Socrate sia mortale sapendo che Socrate è un uomo. Alla macchina basta semplicemente mettere in pratica la regola e ci dà la risposta.
È possibile anche lavorare con le relazioni, come in questo caso:
likes(dan, sally).
likes(sally, dan).
likes(josh, brittney).
dating(X, Y):-
likes(X, Y),
likes(Y, X).
In questo caso scriviamo che esiste una certa relazione tra due atomi, come ad esempio dan e sally, oppure josh e brittney. Successivamente diamo come regola il fatto che le due persone saranno fidanzate solo se l’amore viene ricambiato. Cioè se a X piace Y e se a Y piace X. Nel caso di dan e sally è confermato dai fatti sopra indicati, mentre nel caso di josh e brittney non è valido.
L’intelligenza artificiale mette in campo una serie di problemi che sono sempre stati di natura filosofica, come la natura dell’intelligenza stessa.
Quello che cambia veramente è che in questo caso possiamo prendere in considerazione molti modelli o teorie sulla conoscenza, l’intelligenza, i concetti o l’ontologia e metterli veramente alla prova per vedere se realmente funzionano.
Questo è il momento di per chi si interessa di filosofia di prendere le teorie e provare a testarle sul serio, nel mondo dell’intelligenza artificiale.
Foto da Pixabay, di Roderick Chisholm.